‘How do I deal with unplanned work?’ is a question I hear quite often from the teams I train or coach. The answer is not as simple as it may seem. First thing to understand is that unplanned work is rarely a problem per se. Usually, it’s just a symptom of the true issues that are hidden from sight. It is crucial to figure out what is causing unplanned work. Only then we can tackle the source of the problem from the right angle. Or just leave it for good and master how to live with it (surprisingly, in many cases it is the most reasonable option). In this article we’ll examine different strategies a team can employ to handle unplanned work.
Note: For the reader’s convenience I’ve also created the mind map of this article. So if you feel this long read is too long for you to digest or just want a short summary you can get back to it later here.
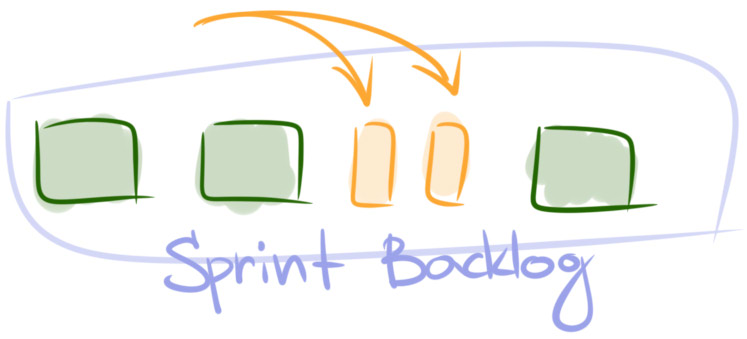
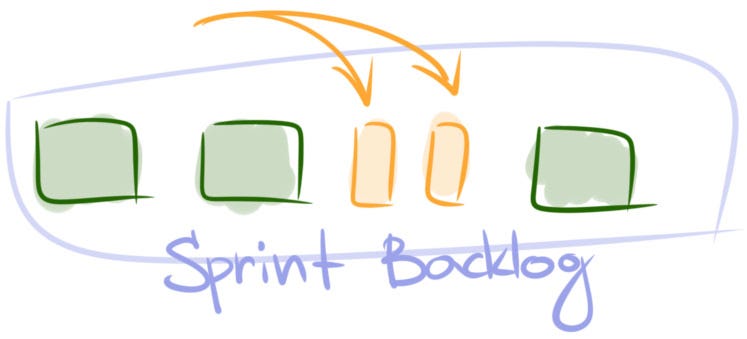
On the Spot Actions and Quick Fixes
The strategies in this group will help you quickly stabilize the team’s flow at low cost. They are not intended to fix underlying issues, but quite often that’s just as much as you need. Sometimes, though, after you’ve applied a quick fix, you should look into a more robust solution.
1. Absorb
Example 1.1. A team is half way through a sprint. Suddenly, a user reports a bug for a recently released feature. It’s not too big. It’s not too small either. There’s a feeling if it’s not fixed immediately, it will be buried in the Product Backlog. The product owner asks the development team to fix the bug as soon as somebody gets available.
Example 1.2. A team completes a user story and demonstrates it to stakeholders in order to get fast feedback. Turns out, some important details had been overlooked during the refinement of the story before the implementation started. As a result, it doesn’t exactly match the expectations. The stakeholders ask the team to add the missing part before the story is completed.
What to do. Let the team absorb the new work.
When to apply. Uncertainty is inherent to the process of software development. The main reason of early demos is to identify smaller inconsistencies as in Example 1.2 earlier so that fixing them is less costly. And if a team follows an Agile process, it should be ready to harness the opportunity to use early feedback to its own advantage (as one of the Agile principles states). The other thing Agile teaches us is if a team feels comfortable, no additional process is necessary. It may be much easier to fix the bug from Example 1.1 than start a negotiation and prioritize it into the product backlog. So, as long as the size of new work is small enough or a team can handle the scope increase without putting the sprint goal at risk, no specific actions are required.
Perspective. Sprint. Non-action.
Costs and risks. A team might not deliver everything that has been planned for a sprint. However, this shouldn’t be an issue in the long run. If a team uses historical data to plan future sprints, this data should quickly accumulate the information about absorbed work. Simply put, velocity will drop a little and stabilize at a new slightly lower level. Plannings will automatically account to this fact and in a couple of sprints the effects of absorbing won’t be a problem.
2. Break Up and Carry Over
Example 2.1. Like in Example 1.2, a team completes a user story and demonstrates it to stakeholders. This time they figure out the story misses a large chunk of functionality, which is critical to release. Again, the stakeholders ask the team to implement the missing part.
What to do. Complete the original user story as agreed on the planning. Separate all the additional requirements off to a new user story and plan it for the upcoming sprints.
When to apply. If the size of new work is comparable to a size of an average user story, it should be turned into a new backlog item. One of the crucial concepts behind a sprint is to let the team focus on the work. Changes that are big enough may and will break the team’s flow. The other reason is to prevent local scope creep. A user story should stay focused around its target (the ‘I want’ clause). If more requirements are added to it, there’s always the risk to swell it so much that it will never be completed at all, even partially. That’s why carrying the work over to the next sprint is a better approach here.
Perspective. Sprint. On the spot action.
Costs and risks. Large size of new requirements likely means that the new part is relatively important and releasing just the initial story no longer makes sense to the end user. Stakeholders won’t be happy to know that the release of the entire feature they actually want (including initial and new requirements) may be delayed for a sprint. At the same time, it’s not uncommon when a new user story turns out to be not as critical as it seemed at first glance. In such case it can safely wait for a few more sprints. In any case, it’s the product owner’s responsibility to set correct expectations with stakeholders.
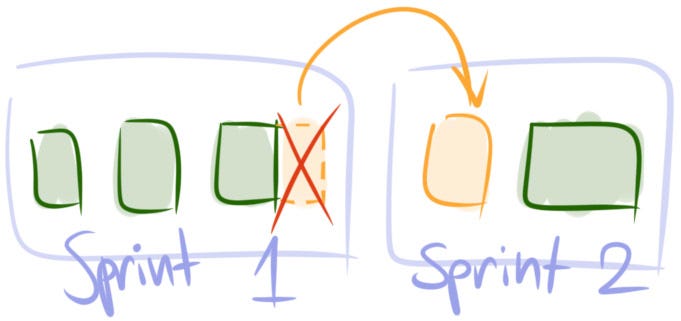
3. Replace
Example 3.1. On the second week of a sprint stakeholders report a critical bug. It becomes clear that the fix isn’t going to be easy. Developers estimate it will take considerable amount of time. But the team has no choice. They start fixing the bug.
Example 3.2. In the middle of a sprint a product owner comes to a team with a request. She has discovered that a new feature must be completed with top priority and asks to add it to the sprint.
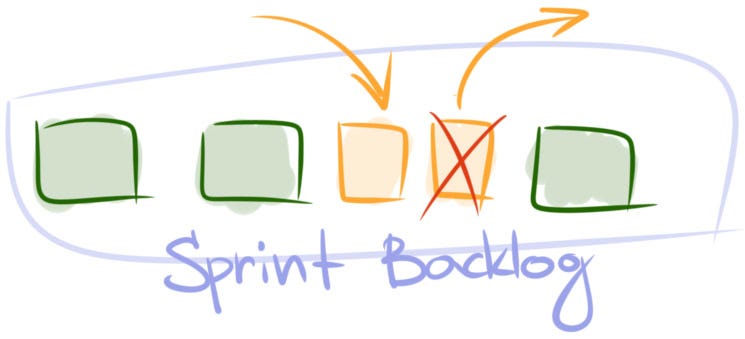
What to do. Add the new user story or bug to the sprint. Then decide what other story or stories of the same size can be sacrificed and remove them from the sprint. You may put the removed items at the top of the backlog or plan for the next sprint right away.
When to apply. Using this strategy is pretty straightforward. Whenever there’s a need to insert a piece of work that is big enough, remove from the sprint something of the same size. You may ask what is ‘big enough?’ A product owner won’t know the answer. It’s the development team’s responsibility to make this decision.
Perspective. Sprint. On the spot action.
Costs and risks. The replaced user story apparently is not going to be delivered in the sprint it was planned for. As with Break Up and Carry Over, some additional stakeholder management may be necessary.
4. Plan a Buffer
Example 4.1. A team has planned a sprint and started development. In a few days a user reports a high priority bug. The team replaces a planned user story with the bug and carries on. In a few more days a couple more bugs are found. The situation repeats several times and a large chunk of the sprint backlog ends up not being delivered. During the next retrospective the team figures out it’s been the same way for several sprints so far.
Example 4.2. A team has owned a back-end system for a long time and has become the center of expertise for all back-end related questions. Unsurprisingly, as soon as each new sprint starts, the team gets bombarded by other teams asking for help.
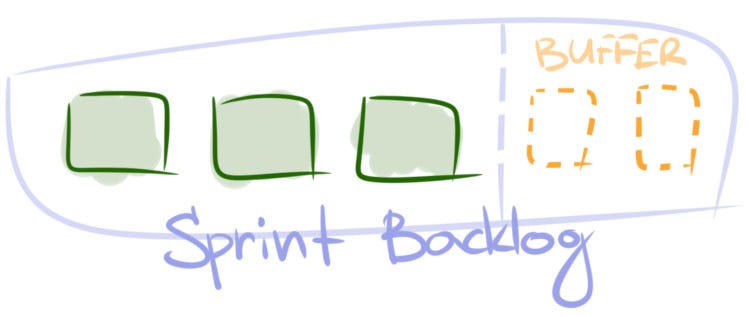
What to do. During sprint plannings reserve some buffer in a sprint backlog. There are two ways to do this. First, you can plan a virtual backlog item of a certain size that will count towards your velocity. This is going to be your buffer. Each time a new user story or bug enters the sprint, you subtract its size from the buffer item until it reaches zero. From this point all the new work will be rejected by the team and put to the product backlog. Second, you can simply plan fewer items than the usual sprint velocity. During the sprint you just absorb new user stories. This difference between average velocity and forecast velocity will act as an implicit buffer.
When to apply. Try out a buffer when the situation is repetitive, unplanned work is intrinsically unavoidable, and the size of unplanned stories is significant. Possible examples are: the team holds unique expertise and must consult other teams; market fluctuations make it hard to produce reliable forecasts even for a couple of weeks. The rule of thumb is the buffer shouldn’t take more than 20–30% of the team’s velocity and at the same time sprint goals should remain achievable.
Perspective. Temporary. Quick fix.
Costs and risks. Obviously, delivery rate of the roadmap items will drop proportionally to the buffer size. This may not be a problem per se but there’s a dark side to it. Unexpected work often comes from organizational or technical inefficiencies, such as cross-team dependencies, legacy source code, or low product quality. When we introduce buffers, we effectively waste up to third of own time on firefighting instead of producing value and fixing real issues. That’s why you should always consider this strategy a quick fix. Another reason to be careful with buffers is that they are hard to maintain, especially when you decide to plan the size. Planning buffer size relies on implicit assumption that a team will be able to control demand when the size reaches zero. In reality, I’ve never seen a team that could efficiently control the pressure of urgent unplanned work once the buffer overflowed. What essentially happens, instead of forecasting just one highly volatile variable — sprint velocity — you are now bound to forecast two. Hence, in many cases Replace is a better option as an on-the-spot action. But if you aim at a long-term solution, you should always look for ways to apply Continuous Improvement Actions from the list below.
Continuous Improvement Actions
The strategies in this group require significant effort and a lot of time to bring positive results. They aim at fundamental dysfunctions in the team’s development process. The common place for all these strategies is that they are best suited when unplanned work is significant, the situation is repetitive, it constantly breaks the team’s flow, and hampers sprints execution.
5. Improve Prioritization
Example 5.1. A team completes a sprint planning. Three days into the sprint the product owner suddenly comes to the team with a whole bunch of new user stories. She says, the priorities have changed unexpectedly. At the end of the sprint the team realizes they have nothing to deliver.
Example 5.2. A couple of days after a sprint has begun a product owner asks to include a user story in the sprint. Some stakeholder has asked to implement it urgently. In a couple more days the product owner comes with a similar request. This time it’s a different stakeholder, but the story is as urgent as the first one. This repeats a few times during the sprint. The result doesn’t come as a surprise. In the end of the sprint the team has completed half their usual velocity.
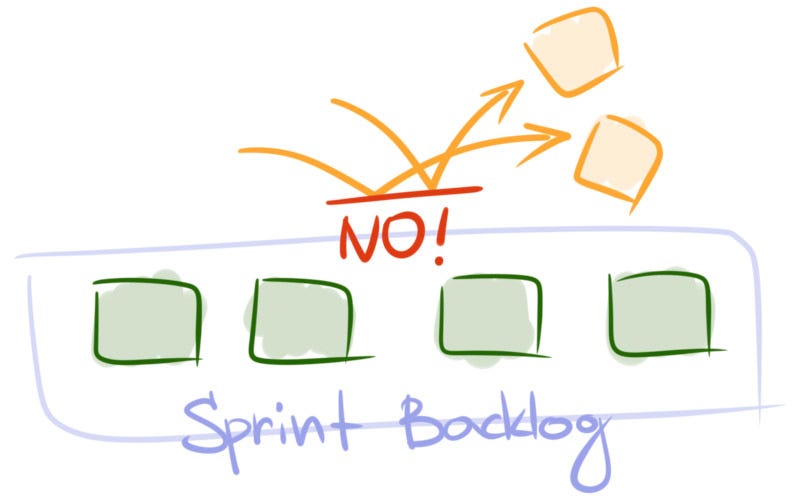
What to do. Work with a product owner to help her learn how to say “No”. Work with the stakeholders to set correct expectations about delivery. Explain that the team can only accept urgent items occasionally. If necessary, agree on what an urgent item means and how frequently the team can handle them.
When to apply. There can be different examples, but the characteristic they share is they almost exclusively come either from a product owner or from stakeholders. Then, after new items have been completed, they sit idle and wait for something else to happen. For example, for another team to complete their user stories for a bigger feature to become marketable. In reality, more often than not new items are not as urgent and can easily wait till the next sprint.
Perspective. Product life-cycle. Fixing root cause.
Costs and risks. Requires coaching of a product owner and negotiating with stakeholders. This may be a challenging task. Since it involves changing human behavior, don’t expect fast results.
6. Improve Quality
Example 6.1. A team gets numerous bug reports during a sprint. Many of them appear to be critical and require immediate fixing. In a retrospective the team comes to realization this has been happening again and again over the course of several sprints. Bugs has become a major nuisance. They disrupt the team’s flow and affect delivery. You can see this clearly in burn down and velocity charts. Sprints feel chaotic. The team loses sense of control over what they do.
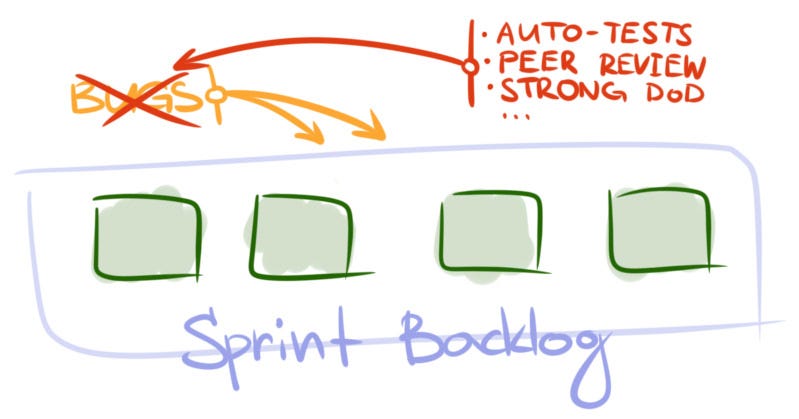
What to do. Analyze the causes for low quality (for instance, using Causal Loop Diagrams). Is it because the team experiences too much pressure from the business and cuts each and every corner to meet deadlines? Is it the automated tests that don’t provide enough coverage? Perhaps, it’s because there’s an infrastructural issue that makes the application crash once in a while? Once the sources have been identified, invest time in removing them. Try different strategies. Most likely, there’s no single source of bugs and you will need different approaches to remedy the problem.
When to apply. It’s not that hard to notice when quality is the culprit. You will start seeing critical bugs popping up more and more often during sprints. They will break the flow and make achieving sprint goal almost impossible.
Perspective. Product life-cycle. Fixing root cause.
Costs and risks. Finding the source of defects may not be easy. Even harder is to implement the remedying actions. If a team observes influx of defects massive enough to disrupt the flow, it means it already took enough time for the negative effects of poor decisions to accumulate. It’s going to take significant effort to revert the situation. This will cause the delivery to slow down, sometimes dramatically. At this point a team will have to make the trade-off. Do they want to fix the problem and get the product back to maintainable state at the expense of velocity? Or they will take the risk and hope that they will be able to keep the defects at bay until the end of the products life-cycle? If a team chooses the second option, they will have to fall back to Plan a Buffer. You should remember, though, that the slowdown caused by poor quality may outgrow the slowdown caused by fixing it much sooner than expected.
7. Remove Dependency
Example 7.1. As in Example 4.2, an expert team owns a back-end system. There’s a downstream team that has started developing a new microservice recently. That microservice uses back-end as the data source. Pretty soon they realize that back-end lacks a lot of data they need. Requests to implement yet another endpoint or add yet another field to an entity become too frequent and start to distract the expert team noticeably.
Example 7.2. A team owns system’s infrastructure. They get constantly interrupted by other teams. A typical request is to update settings of a subsystem and rebuild the application. Tasks like these are quite simple but time consuming and there’s a lot of them.
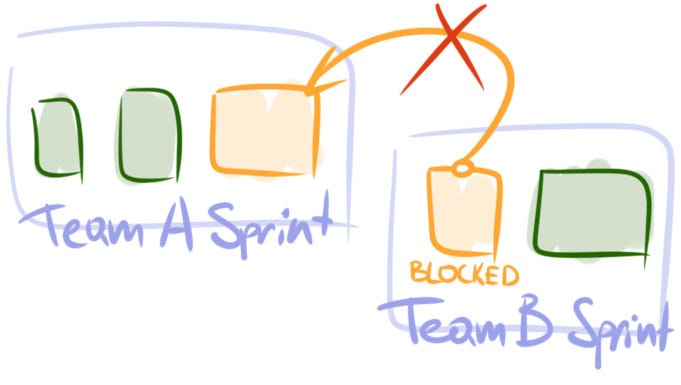
What to do. First, you want the dependent team own their piece of work as much as possible. Give them all necessary permissions and access to the shared code base. Delegate responsibilities and decision making. For example, let them deploy the subsystem they manage on their own instead of reserving this right to a dedicated infrastructure team. Train them to develop in the shared code base and perform delegated activities. Set up the process of code review to avoid drops in code quality. A developer from an expert team may join a dependent team to quickly boost its expertise and make cross-team code reviews less necessary. Second, look for technological ways to cut the dependency between the two teams. Without it many of the steps mentioned above won’t be possible. Although, even decoupling subsystems in itself may help the teams become more independent. For instance, in Example 7.2 the dependent team may move some of the built-time settings to run-time. As a result, they will be able to fine tune the application settings themselves, without involvement of an infrastructure team.
When to apply. As the name suggests, this strategy is a good fit when unplanned work comes in a form of requests from a downstream team. Typically, these requests are blockers for the team that creates them.
Perspective. Product life cycle. Fixing root cause.
Costs and risks. Both teams will need to spend and effort to remove the dependency. This includes knowledge transfer sessions and trainings, studying the new code base, and implementation of technological improvements. Moving a team member from one team to another also takes time for both teams to get used to the new setup. This may influence velocity of both teams. In addition, since any changes in the team’s structure may trigger the reforming process, there is always the risk to spark a conflict that will require specific attention.
8. Adapt the Process
Example 8.1. A team experiences constant interruptions during sprints. Sprint goals become obsolete and sprint backlogs get completely revamped as a result several times a sprint. Unplanned work mostly comes from the product owner. Thorough analysis brings the team to understanding that they can do nothing about it. The fact of the matter is, the team develops a product in a young industry where competition is fierce. Delaying a critical feature for even a few days may kick the company out of the business.
Example 8.2. A team works on a long-lived product with a huge legacy code base. They’ve tried every known good practice and work hard to improve. Despite all efforts, the amounts of technical debt and the scale of the product make it nearly impossible to complete even the smallest user story in a sprint. The problem lies outside of the team’s reach. It has been escalated multiple times, and a special initiative has been launched to alleviate the problem. Some positive effects are already visible, but the progress is just too slow. The team comes to realize that it’s not going to improve overnight. They need to deal with the situation at hand somehow.
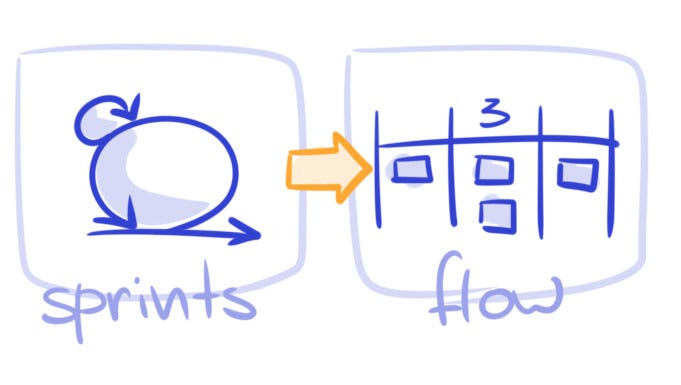
What to do. Try out something different. Get rid of iterations and start using Kanban method. Running sprints is not the only way to do development.
When to apply. The main focus of this strategy is to adapt to the objective reality. You want to apply it when unplanned work is intrinsically unavoidable and is dictated by external conditions that are out of your control. Here goes the caveat, though. In ideal circumstances you should only resort to changing your process when you either want to adapt to the market or get a leverage over the market. In real life there’s always a variety of factors and choosing to Adapt the Process still can be justified. You may decide to employ this strategy in the situation as in Example 8.2. However, you should realize that this is a temporary measure that will help you remove unnecessary burden from people and buy some time to implement real improvements.
Perspective. Product life cycle or temporary, depending on the goal. Avoiding root cause.
Costs and risks. There’s a reason this strategy is listed last. Although it may be the actual solution for you, you should apply it with caution and out of deep awareness. You must be absolutely positive that it’s the external circumstances that cause the change. Don’t fall into the trap of confusing your own issues with objective circumstances. Remember, that applying this strategy is always costly and may be risky, as it puts a team into a new context and may trigger reforming. Team’s performance most likely will decline and it will take time to accommodate to the new ways of working. So, before trying to change the process, always perform a thorough analysis of the situation and try out other strategies from this list. Otherwise, you put yourself at risk of merely masking existing issues without solving the real problem.